
Deep-Learning-Dynamic-MRI-Reconstruction
Published:
Deep-Learning-Dynamic-MRI-Reconstruction

This is a repository for the project “Deep Learning for Dynamic MRI Reconstruction” as part of the course BME1312 Artificial Intelligence in Biomedical Imaging at ShanghaiTech University. The project focuses on using deep learning techniques to reconstruct dynamic MRI images from undersampled data.
This project uses deep learning to reconstruct high-quality dynamic MRI images from undersampled data. We propose a deep-learning-based denoising framework combining two independent UNet modules and a 3D ResNet to explore the temporal correlation. We generate variable density undersampling patterns with acceleration factor 5 and 11 central k-space lines, analyze the resulting aliasing artifacts, and evaluate reconstruction performance with PSNR and SSIM metrics. Additionally, we investigate the effects of dropout, dynamic learning rate schedules and compare L1 versus L2 losses.
TO START
- Clone the repository and download the dataset from here
Our dataset cine. npz is a fully sampled cardiac cine MR image with the size of [nsamples, nt, nx, ny] where nsamples is the number of samples, nt is the number of frames, nx and ny are the dimensions of the image.
- Install the required packages:
pip install -r requirements.txt - Run the training script:
python train.py output
After that, you can find the undersampled images, reconstructed images in the image folder, and the training log in the output folder. We also provide the full sampling images and both real and imaginary parts of the UNet-reconstructed images in the image folder for reference.
- Analyze the results by comparing the reconstructed images with the original images. You can use metrics like PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) to evaluate the quality of the reconstructions, both of them are provided in the output.txt file.
Variable Density Random Undersampling Pattern Generation
We generate a variable density random undersampling pattern (U) with the size of the given cine images for acceleration factor of 5. Eleven central k-space lines are sampled for each frame. Each sampling pattern must be a matrix with 1s in the sampled positions and 0s in the remaining ones.
We also plot the undersampling mask for one dynamic frame and undersampling masks in the ky-t dimension. 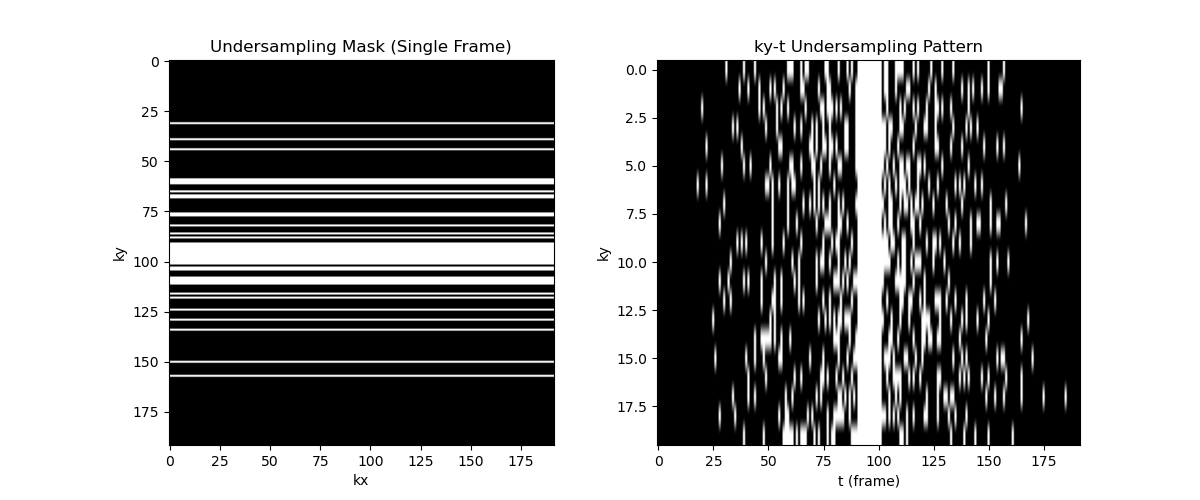
We also obtained the aliased images as a result of the undersampling process with the generated patterns. For this we use the formula:
\[b = F^{-1} \cdot U \cdot F \cdot m\]where $b$ is the aliased image, $F$ is the Fourier transform, $U$ is the undersampling mask, and $m$ is the original image. The aliased images are then used as input to the deep learning model for reconstruction.
Below are some examples of the aliased images generated from the original images.

Fig: Aliased image resulting from 5x undersampling of the cardiac MRI data
And here are the comparison of the aliased images with the original images. We also show the sampling masks for some frames. It is noticeable that different frames have different sampling masks, which is a key feature of our approach to Deep Learning based reconstruction.
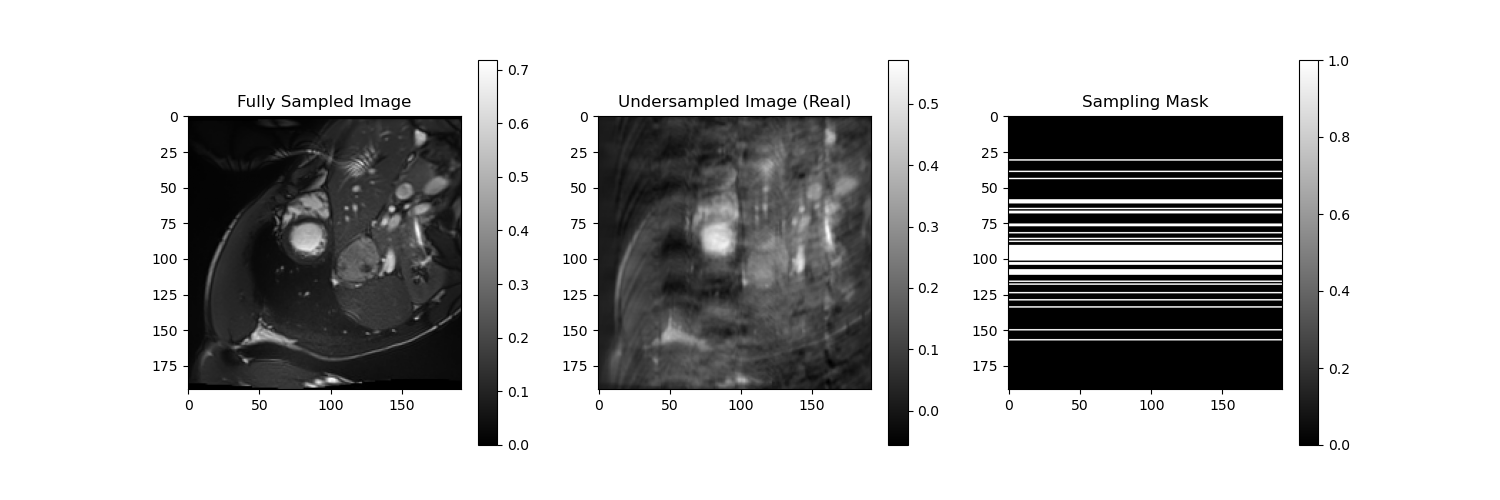
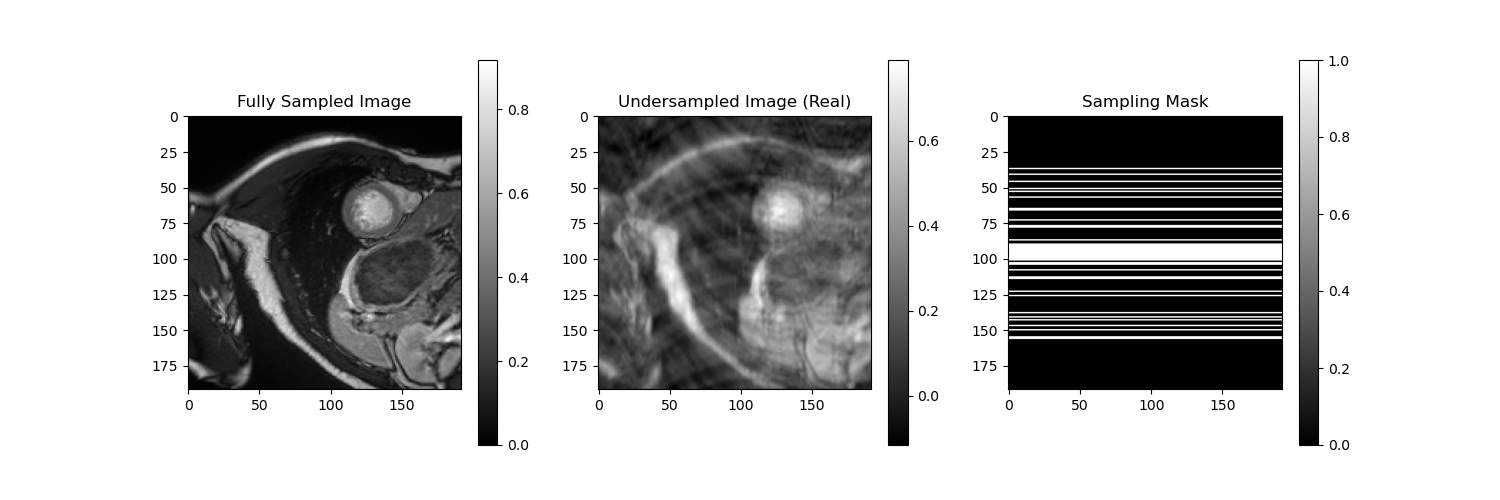

Fig: Comparison between fully sampled (left), undersampled (middle), and corresponding sampling mask (right) for frames

Fig: Multiple sampling masks showing the variable density patterns across different temporal frames
It is also clear to see that, for different dynamic frames, the undersampling masks are different.
Reconstruction Network
All the details of the network are in the train.py file.
To explore the temporal correlation, we chose to stack the dynamic images along the channel dimension. However, this brought out a problem as the input image is pseudo-complex, and the real and imaginary parts are not aligned. To solve this, we split the input into two branches, one for the real part and one for the imaginary part. The two branches are then concatenated at the end of the UNet structure. We added attention mechanisms to the bottleneck layer of the UNet structure to better capture the spatial correlation and channel correlation.
However, UNet is a 2D structure, and the temporal correlation is not well captured. To solve this, we added a 3D ResNet structure after the UNet structure to better achieve this goal.
So in general, the reconstruction network consists of three components:
Dual 2D UNet Architecture (Real & Imaginary Components)
Purpose: Process the real and imaginary parts of the complex MRI data
Features:
- Encoder-decoder structure with skip connections
- Attention mechanism in the bottleneck layer
- Dropout (p=0.3) for regularization
- LeakyReLU activation (negative_slope=0.1)
- Weight Regularization for better training stability
- Channel and spatial attention modules
3D ResNet (Temporal Fusion)
Purpose: Integrate temporal information across the MRI sequence
Features:
- 3D convolutions to process the temporal dimension
- Residual connections for better gradient flow
- Lightweight design with one residual block per layer
- Final 1×1×1 convolution to map features to output channels
The whole structure is shown in the figure below.
Fig: Detailed architecture of our reconstruction network showing dual UNet branches for processing real and imaginary components separately, followed by a 3D ResNet for temporal fusion across frames
Training and Evaluation
Below are the details of the training parameters:
train(in_channels=20,
out_channels=20,
init_features=64,
num_epochs=800,
weight_decay=1e-4,
batch_size=10,
initial_lr=1e-4,
loss_tpe='L2'
)
Using the above parameters, we achieved a PSNR of 29.08446121 and SSIM of 0.84434632, which is a remarkable improvement over the aliased images. The whole training process took about 2 hours on a single NVIDIA RTX 2080 Ti GPU. More detailed results can be found in the output.txt file. We are also happy to show you some of the reconstructed images compared to the original images.

Discussion on the Effect of Dropout, Dynamic Learning Rate Schedules, and Loss Functions
We investigated the impact of several training components on the reconstruction performance: dropout, dynamic learning rate schedules, and the choice of loss function (L1 vs. L2).
Impact of Dropout and Dynamic Learning Rate
We trained a model variant without dropout and without a dynamic learning rate schedule (using a constant learning rate). The training and validation loss curves are shown below:

Performance Metrics (No Dropout/Dynamic LR):
- Loss: mean = 0.00343, std = 0.00127
- PSNR: mean = 24.154, std = 1.858
- SSIM: mean = 0.743, std = 0.037
Analysis:
The validation loss curve shows significant fluctuations and a tendency to increase towards the end of training, indicating overfitting. Compared to the original model (PSNR: 29.08, SSIM: 0.844), the performance is considerably lower. This highlights the importance of dropout for regularization and dynamic learning rate schedules for stable convergence and avoiding overfitting.
Impact of L1 vs. L2 Loss Function
We trained another model variant using the L1 loss function instead of the default L2 loss, while keeping dropout and the dynamic learning rate schedule active.

Performance Metrics (L1 Loss):
- Loss: mean = 0.02228, std = 0.00549
- PSNR: mean = 29.151, std = 2.241
- SSIM: mean = 0.84389, std = 0.042
Performance Metrics (Original L2 Loss):
- Loss: mean = 0.00135, std = 0.00055
- PSNR: mean = 29.084, std = 1.932
- SSIM: mean = 0.84434, std = 0.037
Analysis:
The L1 loss values are inherently larger than L2 loss values, which is reflected in the mean loss. However, the PSNR and SSIM achieved with L1 loss are very similar to those achieved with L2 loss.
In our experiments on dynamic MRI reconstruction, we observed an interesting fact that using L1 loss led to higher PSNR but lower SSIM compared to using other loss functions.
This phenomenon can be explained as follows:
PSNR (Peak Signal-to-Noise Ratio) measures pixel-wise accuracy and is closely related to the mean squared error (MSE). Although L1 loss optimizes absolute error instead of squared error, it still effectively reduces the overall pixel-level discrepancy, thereby improving PSNR.
SSIM (Structural Similarity Index) evaluates the structural similarity between images, focusing on local patterns of luminance, contrast, and structure. While L1 loss minimizes the global error, it does not explicitly encourage structural consistency. As a result, even small spatial misalignments or distortions — which may have little impact on PSNR — can lead to a noticeable drop in SSIM.
In short, L1 loss favors pixel-wise precision but may compromise local structural integrity, which explains the observed trade-off between higher PSNR and lower SSIM.
To address this, one potential solution is to design a composite loss function that balances pixel accuracy and structural preservation, such as combining L1 loss with SSIM loss or perceptual loss based on feature space similarity.
The training curve appears stable. While L1 loss can sometimes promote sparsity, L2 loss often leads to smoother results and is more sensitive to large errors. In this case, both loss functions yield comparable high-quality reconstructions, but the original configuration with L2 loss achieved slightly better stability (lower standard deviation in metrics) and significantly lower loss values.
Ultimately, the choice of loss function should be guided by the final objective of the task:
If precise pixel recovery is the goal, prioritizing PSNR with L1 or L2 loss may suffice.
If maintaining perceptual quality and structural fidelity is crucial (e.g., in clinical imaging), incorporating structure-aware losses is strongly recommended.
Creativity: Comparison with Attention Mechanisms
To evaluate the impact of attention mechanisms, we incorporated channel attention and spatial attention modules into the baseline network. These modules were added to the encoder-decoder structure of the UNet branches to enhance feature representation by focusing on the most informative regions and channels.
The performance metrics for the attention-based model are compared with the baseline (optimized with dropout and dynamic LR) in the table below.
| Model | PSNR mean | PSNR std dev | SSIM mean | SSIM std dev |
|---|---|---|---|---|
| Baseline (Optimized) | 29.08446121 | 1.93235576 | 0.84434632 | 0.03711063 |
| Attention-Based | 32.38721751 | 1.87722389 | 0.89100512 | 0.03601302 |
Discussion
- PSNR Improvement: The attention-based model achieved a higher mean PSNR compared to the baseline, indicating better pixel-wise reconstruction accuracy.
- SSIM Improvement: The mean SSIM also improved, suggesting that the attention mechanisms helped preserve structural details more effectively.
- Stability: The standard deviations for both PSNR and SSIM were slightly lower in the attention-based model, indicating more consistent performance across the test set.
Conclusion:
The experiments demonstrate that dropout and dynamic learning rate schedules are crucial for achieving optimal performance and preventing overfitting. Both L1 and L2 loss functions can lead to good results, with L2 providing slightly more stable performance metrics in our final configuration. The original setup (with dropout, dynamic LR, and L2 loss) provided the best balance of performance and stability.
Unrolled Denoising Network with Data Consistency Layer
We explored an unrolled network architecture incorporating data consistency layers between cascaded instances of our base reconstruction network. This approach aims to iteratively refine the reconstruction by enforcing consistency with the acquired k-space data after each denoising step.
We trained models with 2 cascades (Cascade 2) and 3 cascades (Cascade 3).
Cascade 2 Results
- Training: Required 18GB GPU memory, trained for 300 epochs. Average time per epoch: ~12 seconds.
- Performance Metrics:
- Loss: mean = 0.00143, std = 0.00057
- PSNR: mean = 28.866, std = 2.048
- SSIM: mean = 0.834, std = 0.030
Cascade 3 Results
- Training: Required 24GB GPU memory, trained for 300 epochs. Average time per epoch: ~360 seconds (6 minutes).
- Performance Metrics:
- Loss: mean = 0.00137, std = 0.00051
- PSNR: mean = 28.958, std = 1.813
- SSIM: mean = 0.807, std = 0.041

Comparison and Discussion
| Model | Epochs | Avg Epoch Time | GPU Mem | Loss (mean ± std) | PSNR (mean ± std) | SSIM (mean ± std) |
|---|---|---|---|---|---|---|
| Original | 800 | ~6 sec | ~10GB | 0.00135 ± 0.00055 | 29.084 ± 1.932 | 0.844 ± 0.037 |
| Cascade 2 | 300 | ~12 sec | 18GB | 0.00143 ± 0.00057 | 28.866 ± 2.048 | 0.834 ± 0.030 |
| Cascade 3 | 300 | ~360 sec | 24GB | 0.00137 ± 0.00051 | 28.958 ± 1.813 | 0.807 ± 0.041 |
Observations:
- Increasing the number of cascades significantly increased GPU memory requirements and training time per epoch.
- Both cascaded models were trained for only 300 epochs due to time and resource constraints, compared to 800 epochs for the original model.
- The performance (PSNR, SSIM) of the cascaded models did not surpass the original single network. Cascade 3 showed slightly better PSNR than Cascade 2 but worse SSIM than both Cascade 2 and the original model. The validation loss for Cascade 3 also appears less stable than the original model’s later epochs.
Potential Reasons for Limited Improvement:
- Insufficient Training Data: The dataset size (200 samples) might be insufficient, especially for deeper unrolled networks. Data augmentation using more undersampling masks could potentially help.
- Base Network Complexity: The original network is relatively large. It might not have fully converged even after 800 epochs, potentially reaching a local minimum sufficient for good performance but hindering effective iterative refinement in the unrolled setting.
- Training Constraints: Limited training epochs (300 vs. 800) due to significantly increased training time and memory usage likely prevented the cascaded models from reaching their full potential convergence.
Further investigation with more extensive data augmentation, potentially a smaller base network, and longer training times would be needed to fully evaluate the potential of the unrolled architecture.